Semistructured
data
|
| |
Speaker: Jennifer
Widom
Typical data base systems assume
a well-structured data, with a fixed schema, defined in advance. They depend on this
to organize the data structures, index it, and process queries.
Semistructured data is very common today. It has rapidly changing
structure, or a structure, which is not fully known when the data is collected. Instead
of a fixed schema, objects contain their own schema, which you get when you download
the objects.
Typical structures are structures of objects and links between the objects. And this
is actually isomorphic to the data structures described by the XML (eXtensible Markup
Language). (XML currently
expresses trees, but the speaker thinks that general structures of objects and links
are going to come as extensions to XML.)
Query languages: UnQL, Lorel, MSL, StruQL, rather similar languages.
The author has been working with the Lorel language. These languages navigate the
graph structure of the data base. Example:
select DBGroup.Member.Project
where DBGroup.Member.#.(Office|Room) grep "252"
XML has actually attributes and
subobjects.
The speaker used as an example Microsoft's
demo page of XML on the web.
The demo is an on-line auction, with lists of items and current high bids for them.
Advantage with query languages: You do not have to write new code to make new kinds
of queries, all you have to do is to formulate a query in a simple query language.
Large software companies like Microsoft and IBM are probably working on developing
their own query languages, so the issue of which query language will succeed may
depend on politics, but also these languages get ideas from each others, so the basic
ideas of such languages in the future will probably be similar to those developed
today in the research community.
In Lorel, there is a "Data Guide" which is a kind of
dynamic schema, being developed as data is collected.
|
|
Web-based
Information Services
|
| |
Speakers: Ozsu,
Kerr, Gal, Mylopoulos, Gruser, Raschid, Vidal, Bright, De Roa, Catarci, Iocchi, Nardi,
Santucci, Huck, Fankhauser, Aberer, Neuhold.
Data base people are so happy
with XML. The reason is that XML imposes at least some structure to the information
available on the web.
However, this can be misleading, because two different XML pages may be using the
same tags for completely different purposes.
Can heterogeneous web structures be merged?
A toolkit which will make a web source look like a data base. Example:
weather.com. Instead of having to follow links to find the weather in a particular
place, the query language will create a data base, from which you can directly get
answers to queries like "Get me the weather of Washington D.C.". If I understood
the talk rightly, they have to manually define the schema and the extractors for the web pages they want
to access, and then these
can be used to get data from a particular web site. Example:
- HTML document contains
a TABLE, whose title is Maryland.
- Each row of the table
corresponds to a city.
- The second column of
each row corresponds to the weather of that city.
One extractor may need to call
another extractor. Complex extractors will include conditionals and iterations.
One goal is that instead of having to browse the web for hours
to get a small page of information, I want to just ask the query to the web and get
the answer. This is what data base people can do with data bases, why can't you do
the same thing on the web?
| |
Surfers |
|
help in navigation |
| |
Hunters |
|
query capabilities, application
domains |
| |
Information brokers |
|
specific domains |
The system is not capable to handle
a completely unknown domain. It has to have some knowledge of the domain in advance.
Important is to be able to apply the same structure to different
information sources. For example, two product catalogs from different manufacturers
may have very different web-presented structure, but if a user is to be able to search,
using a consistent search method, they have to be mapped onto conformant data structures.
Possible extraction methods: Regular expression based pattern matching,
context free grammar parsers.
|
|
Agents
|
| |
Speakers: Tesch,
Aberer, Au, Liang, Npurameswaran.
Decision autonomy is not considered
in traditional transaction and workflow technology. The goal of agent technology,
said the speaker, is to avoid agents from unilaterally defecting. Simple architecture:
![[Agent A]<-->[Agent B]](co-sys-1.gif)
More complex architecture:
![[Agent A]<-->[Contract Broker]<-->[Agent B]](co-sys-2.gif)
Protocols should
maximize overall benefit and distribute benefit equally.
The contract manager should reduce defections by making them non-beneficial to all
participating agents. The
contract manager compares different state changes, and choses the state change which
will maximize the product of the benefit for each of the two participating agents. Problems not yet considered: Lies and
more than two agents. The speaker said that it would probably be difficult to find
state changes which are beneficial to all agents, if there are more than two agents.
(My comment: Maybe this is the reason why natural selection has developed two genders
in most species. But a few species have more than two genders, for example ants.
But then only two of the ant genders can reproduce.)
In a dynamic environment, where the environment changes, large
and complex plans should be avoided. Such plans will often fail in a dynamic environment,
and maintaining them, when the environment changes, is difficult. In a dynamic environment,
plans should
include parallel paths where possible, and optional paths where possible, just as
cooking recipes.
|
|
|
![[Action A]<-->[Action B1]/[Action B2]/[Action B3](Parallel actions)<-->[Option A]/[Option B]](co-sys-3.gif)
|
| |
The speaker had made an experiment
with an agent, which was to succeed in a very dynamic environment, a house on fire.
He found that agents which made too complex plans failed, because they could not
adapt fast enough to changes in the environment (the fire spreading).
One
question from the audience said that stale-mate or loop situations might occur, where
two agents switch back and forward between two plans.
Each switch of plans for one of the agents, changes the environment so that the other
agent switches its plan, and so on. |
|
Future
issues and social considerations
|
| |
Speakers: Jacke,
Sheth, Ouksel, Rusinkiewicz, Woo.
This panel discussion had the topic
of how to evolve research on cooperative information systems into the future, and
whether social issues have been forgotten. Three facets: Cooperation between equals,
management of organizations, systems technology facet (most papers in the conference
use mostly this facet, the speaker said). Systems often fail, because management
and users do not accept it. Example: A complex 30-million-dollar information system
for the police in Germany, which police would not work because of various problems
with it. A reverse case is a cooperative system, developed in Germany, which works
well for cooperation, but does not work in managerial organizations situations, which
it was not designed for.
Another example: A company had difficulty in reacting fast enough
to new features offered by their competitors. The reason: They were limited by the
information systems they were using, which could not easily adapt. |
|
Next
Generation Information Systems
|
| |
Speaker: Alt Silberschatz,
Bell Labs.
This was obviously
a conservative speaker who was accustomed to traditional data bases, and who was
very upset that the WWW is not a traditional data base. Cooperative
Information Systems, in the speakers opinion, is the issue of Interoperability of
data bases. (My comment: If you have a hammer... This speaker obviously has his special
kind of hammer.)
New challenges in the data base area, according to the speaker:
- Multimedia
- Quality of Service
- Information Querying
- Interoperability
- Data Mining
Multimedia data bases must handle
authoring, distribution of data, searching for information. Example "Give me
the set of all movies in which John Wayne is riding a white horse in front of a yellow
house".
None of the operating systems we have today support the required
quality of service, the speaker said. The Internet does not provide consistent response
times, and because of that its quality of service is not good, according to this
speaker. Delay jitter, the variation of delays in getting responses, is an evil.
The speaker wanted to talk about his ideal operating system, Eclipse, which is defined
in order to get quality of service.
Then he talked about CineBlitz, a system for delivery of video
on demand. This requires data bases, which can deliver, at a consistent rate, movies
at normal speed, increased speed, reduced speed or one frame at a time. To realize
this, the speaker said that research was needed on admission control, disk scheduling,
buffer managment, storage management, fault tolerance, and tertiary storage. To provide
this, prefetching is important, the data base must fetch in advance what the user
is soon going to need. Prefetching requires buffers, and the speaker had some formula
for computing the needed buffer size.
Which is the largest planned data base in the world? Answer: It
is the planned archive of BBC of digitally stored television programs. Or perhaps
it is NASAs planned data base which will download 3-4 terabytes of data from sattelites
each day, and store it for seven years. Will they succeed?
Approximate
answers are going to be important in the future, the speaker said. In a distributed
environment, some data sources may be missing, or data is changing in different places
so that you cannot "stop the world" and make a snapshot at any exact time.
This requires trade-offs or accuracy versus performance.
More and more web systems require personalized log ins. This requires
passwords. People will have to remember 50 passwords. Most people use the same password in many
data bases, which of course is not very secure.
Instead, the speaker proposes a data base of passwords, in your personal computer
or in a proxy server, through which all your web requests pass, and which will automatically
deliver the right passwords for each web server you connect to. This system is known
under the name of LPWA. You can also have separate e-mail addresses for each server.
So if you get a lot of spamming to one of these e-mail addresses, just filter out
that address, and use a new address for that data base! (My comment: Sounds dangerous.
You might miss important mail using this method of spam control.)
|
|
Heterogenous
Distributed
Information Systems
|
| |
Speakers: Schek,
Vidal, Raschid, Gruser, Ahmed, Dayal, Critchlow, Ganesh, Musick, Moro, Natali, Sartori.
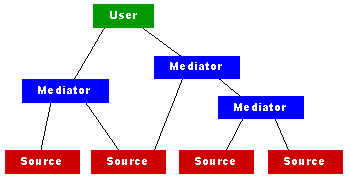
When you get information from multiple sources on the Internet,
you need to be able to perform capability-Based Rewriting (CBR). This will provide
users with a single user interface for multiple sources. Mediators will act like
a kind of proxy servers, and they can be using data from other mediators: |
|
|
|
| |
Examples: A complete
guide of all programs on all channels nationwide, a site with a complete guide of
all educational programs, and a site with in formation about all movies, and a site
with information of all cable channels in a particular area.
Then the speaker began to describe a complex set of formulas for
finding out which queries can be answered, given knowledge about which sources are
complete and for which sources we have a complete description.
Then came a talk about design of a medical data base, which has
to be able to survive system and hardware failures. Concurrent access is needed for
many users. The model sees the data as activities, which are long-lived collections
of data. Within activities, there are "work-in-progres", tasks, and basic
actions are the start, complete, suspend and resume of activities.
Changes in the data base are first done in a personal work-space,
and this personal work-space is not merged with the large data base until consistency
checks can be done.
There was nothing in this speech which described distributed or
concurrent information processes. The reason why this paper was presented on this
conference was that it supported cooperation, which of course almost any application
with more than one user does.
The concurrency problems, according to the discussion which followed
this talk, is what happens if two doctors perform two lab tests on the same patient,
and then prescribe two different treatments for this patient. How this concurrency
problem is solved, must be application-specific, one voice from the audience said.
The next speaker talked about data warehousing in science. Data
warehousen is already well-known techniques in business. But in science, there are
different problems, because data is poorly understood and technology is rapidly evolving.
Scientific data bases is not consolidated into large, well-controlled data baes,
but distributed on many small data bases of variable quality. Example: Correlating
a new DNA sequence against different data bases of known DNA sequences. |
|
Workflow
|
| |
Speaker: G. Piccinelli
The Team Model for Distributed
Workflow Management
Existing workflow systems are
designed for a single company, to be used in intranets. But if you want workflow
systems to assist cooperation with partners (=federation), there are additional requirements.
The speaker had developed a language for specifying federated workflows.
WfMC is an international organisation for the standardisation of
workflow. Their reference model. includes one or more Workflow Languages, and that
is the part of their reference model which the speaker is working on.
The federation requires a kind of glue to keep the parts together.
For each partner there is a process engine, which communicates with processes within
that partners. The process engine communicates with the process engine at other partners.
Fault tolerance requires isolation of the workspace, distribution of the process
logic and shielded access to internal processes.
The Access Interface is the link between the workspace and the
internal processes of an organisation.
A process has three main elements: Task Space, Data Space and Message
Space. The Process Engine does not communicate directly with the Acess Interface,
it communicates with the process, and the process communicates with the Access Interface.
The Task Space contains all and only the tasks an organisation
needs to perform at a given stage of the process. The Data Space contains all and
only the data needed at this stage of the process. The Message Space holds incoming
and outgoing messages.
The basic operators in the process definition language are:
Push (OrgA, OrgB, Obj)
Pull (OrgA, OrgB, Obj)
Message (OrgA, OrgB, Msg)
Service (OrgA, OrgB, Srv, Obj)
Task (OrgX, Act)
The language also has controls
for sequence, choice, procedures, etc. They have written a compiler, which will compile
this language into workflow applications.
A question from the audience: How do you handle exceptions. Answer:
Our system has no handling of exception at the moment.
A Mixed Paradigm Conceptual Workflow
Modeling Language
Speaker: S. Carlsen.
He has designed a visual workflow
modelling language, founded on traditional information system modelling languages.
Its name is APM (Action Port Model). The focus is on supporting organisational processes,
not on automation. The language is based on Actions, which have access to a shared
workspace of information resources.
Interworkflow systems
Speakers: Hiramatsu,
Okada, Matsushita, Hayami
Japanese information systems often
seem to be strongly oriented towards a very hierarchical structure of management.
So, also, this speech, which sees workflow as preparing a document at a low layer
in an organization, and then moving the document for approval to successively higher
levels of management.
This paper discusses how to adapt this to a multi-organization
usage. Each has its own internal workflow system, and its documents are translated
to the format of the interworkflow system, transferred to the other organization,
and then translated again to the internal format of the other organization. Not only
document text, but also auditing and history management data must be transferred.
The author has developed a three-dimensional graphical modeling
tool for describing the Interworkflow system, and has developed the necessary translators
and interworkflow management tools.
It is important to clarify which organization should carry out
which work. The author showed the graphical interface, which has a progress line
for each organisation. Along this line, various activities are placed. Then there
are links, at various stages, from one organization line to another.
|
|
 |
| |
Important is to
secure the autonomy of each organisation. Other organization should not be able to
make decisions on the data in other organisations. For example, if organization MIDDLE
cooperates with two organizations LEFT and RIGHT, then LEFT should not see that RIGHT
exists. So her system specifies separate interworkflow control figures for the LEFT-MIDDLE
and MIDDLE-RIGHT.
Integration of the State Charts
Speakers: Motz,
Fankhauser
If different organizations have
different state charts, these must be coordinated to allow interworking between the
organizations. Each state is described by its pre-conditions: The values of different
variables which must have a certain value for each stage. They have defined methods
of finding equivalences between state charts.
Example: Library, with different state charts for the department
borrowing a book and the library lending the book. Typical states are Book ordered,
Request rejected, Book in stock, Book available, Book on loan, Book reserved, etc.
Two state charts can be parallel, mixed, disjoint, alternative
or consecutive. Equivalence may for example be that the end state of one state diagram
is equivalent to the start state of another state diagram.
Cooperative Design for 3D Virtual
Scenes
Speakers: Luo,
Gali, Mascara, Palmer
A networked application with a
layered design, with a application layer and a cooperation layver below the application
layer. Only modifications are sent between the participating applications. A protocol
has been defined for sending a small set of different graphical operations between
applications. They are using "Open Inventor" as a graphic tool and the
program is written in C++. They have various degrees of control of sending the events,
from asynchronous to totally ordered.
If two users intend to modify the same region at the same time,
problems occur. This is handled by a staged process: You first select an object and
then modify it. You cannot select an object in a subtree which no other member has
previously selected.
|
|
Final
Panel Discussion: Embedding Knowledge in Systems
|
| |
Speakers: Brodie,
Stanley, Dayal, Mylopoulos, Raschid
Current systems are absolutely
chaotic, said Brodie. Systems are interconnected in all sorts of ugly ways. Stop
developing point solutions, develop instead global solutions, he said.
In
each layer, a few or one company is trying to achieve dominance or monopoly. (Word
processing, back office data bases, operating systems, Internet access, etc.) A company
which controls one such layer, is trying to increase its dominance by moving functionality
from other layers to their layer. Example: The current Microsoft effort to move Internet
functionality into the operating system and PC office applications layer.
Mediator technology has had difficulty to scale to multiple heterogenous
sources. Different mediator developers are not even willing to develop mehods for
their mediators to interact with each other.
Another speaker said the same thing I have been thinking, that
many of these data base people in these conferences have very narrow hammers, they
have their specific tools and sees everything from the viewpoint of the data base
tools. |
|