General Issues
|
| |
There was more new and interesting issues in the applications area
than ever before. More difficult to have time to go to all interesting
group meetings.
The IETF language
- Access
- Appropriate
- Architecture
- Bandwagon
- BOF (meeting which does not have an IETF working group)
- Client
- Common area
- Definition
- Existing practice versus new development
- Focus on
- Framework
- Goals and milestones
- Infrastructure
- IRTF (Internet Research Task Force, in IETF used as a label
of things you want to get rid of, because it is too advanced)
|
- Primarily
- Process
- Proprietary protocols
- Rathole (= issue so controversial that no rough consensus
can be expected)
- Requirements and problems
- Restrict
- Server
- Service level
- Terminology
- Tool
- Transaction
- Transparent
- Vendors
- Working group
|
|
Applications Area Open Plenary
|
| |
Recent new working groups: LDAP
application, Instant messaging, Webdav searching, Message tracking.
May soon become working groups:
Mailcap (find capabilities of a certain e-mail recipient), enum (finding
phone number given an e-mail address), web replication and caching,
Kermit over telnet, use of LDAP for routing inside a local domain, domain
registry protocol, human-friendly naming.
HTTP Next Generation has been put
into the Transport area, not the Applications area, since it has a large
impact on the transport protocols. Whether it really should be labeled
HTTP is not clear.
Winding down working groups: It
is important to get rid of finished working groups, since they occupy
the AREA directors' time.
New mailing lists: Finding volunteers
to review papers by joining three lists, web@apps.ietf.org, messaging@apps.ietf.org,
directory@apps.ietf.org, usual request procedure to sign up.
XML bandwagon: People tend to use
XML for everything, and even standards which are not based on XML, are
developing XML ways of conveying their information.
Internationalization:
General guidelines needed. For example, casing is not so simple
in all languages as it is in ASCII. String comparisons and sorting are
related issues. Question: How can we get the ISO 10646 specification
available on-line? Answer: License the Unicode specs, and hope that
ISO 10646 will adopt what Unicode has done. ISO 10646 costs hundreds
of dollars, Unicode about 70 dollars. IETF should decide whether to
reference 10646 or Unicode. Go to "unicode.org" to find the
Unicode working documents. A mailing list will be started and announced
on the IETF list.
Organizational issues:
Split the APPS area? Or add more area directors? An area director
does not really have time to handle more than 7-8 ongoing working groups.
Should IETF be more restrictive on which new tasks to accept for working
groups?
Authentication:
Some people talked above a method called DIGEST, which was said
to provide a less advanced security than using public key encryption.
Authorization: People tend to assume
that once authentication is ready, authorization does not require much
thought. This is not true, and authorization is sometimes not discussed
enough.
|
|
HTTP Next Generation BOF
|
| |
Why? HTTP/1.1 is very complex, and is used for many specialized application
which do not require this complexity.
HTTP-NG will be modular, extensible, including "mandatory"
extensions (=extensions which an implementation which do not understand
them will be required to reject), scalability, network efficiency and
transport flexibility.
There will be three layers:
- Transport (of opaque messages)
- Remote invocation
- The Web application
Transition: Start with a pair of a few popular kinds of WWW agents:
- origin server and high-level proxy
- browser and low-level proxy
- high- and low-level proxy
There were many people who asked questions like "is this really
needed", and "do we need yet another version of HTTP"
and "will you get people to use this new version of HTTP?".
Charter: Collect experience from HTTP and how it
is used, including proxies, caching, firewalls, layering, modularity.
The different pieces will be defined, in bottom-to-top order. Not in
charter: Language mappings, advancing web applications, replacing TCP.
People commenting in the discussion:
"Too much, too many people with good experience
of remote applications will want their ideas into it, so that you will
never finish."
"Why are you only looking at the web application
if you want to develop a general remote procedure call protocol?"
"Why are people using HTTP for so many applications?
Because it is a way to get through firewalls. You want to stop this,
but people will just hide their application high enough to subvert the
firewalls anyway."
|
|
Web Replication and Caching
|
| |
Charter: http://www.terena.nl/tech/wrec
Structures of proxies can be complex, some of them have old, other
new versions of a resource
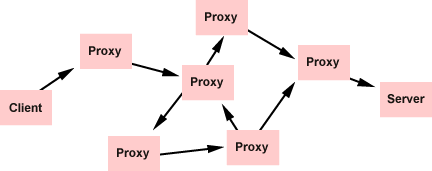
Primary tasks of this working group
- Client-Proxy communication
- Inter-Cache communication
- Caching/replication infrastructure
- Cache-Network Device communication
- PAC
- Script for proxy configuration
- WPAD
- Finding the script (PAC)
- CARP
- Clustered proxies
How to handle peer-master structure
Inter-Cache communication
- ICPv2
- Inter Cache Protocol, documented in RFC 2186, 2187: Protocol to
check whether a cache has an object or not.
- WCCPv1
- HTPC HyperText Caching Protocol draft-vixie.htcp.proto-03, an improvement
on ICP, can handle HTTP headers.
- CARP
- draft-vinod-carp-v1.03
- Cache Digest
- work in progress
- Various other protocols
- CRIPS, Relais, LSAM, AWC
The area manager, Keith Moore, strongly advocated that the group must
decide whether it wants to document existing practice, or develop new
protocols, and that both cannot be done in the same group. To combine
both in the same group does not work well, he said.
|
|
Process for Organization of Internet Standards
|
|
| |
Poisson working group: I only went
to the first of two meetings with this group, so much more was probably
said during the second meeting.
List posting restrictions
Trying to find consensus on which postings are acceptable and not acceptable
to the IETF mailing list, and in which cases the moderator can restrict
postings from people who often break these rules. Committee to decide
whether a certain person should be removed from the list?
Not acceptable:
Promotion, solicitation, private issues.
Acceptable: IETF
policies.
Special topics:
Should normally be discussed in special working groups, but if the working
group wants wider comments on some issue, they can take it up on the
general list.
RFC series
This diagram shows the increase in the first RFC number each year. For
1988, the data is only for the first 10 months.
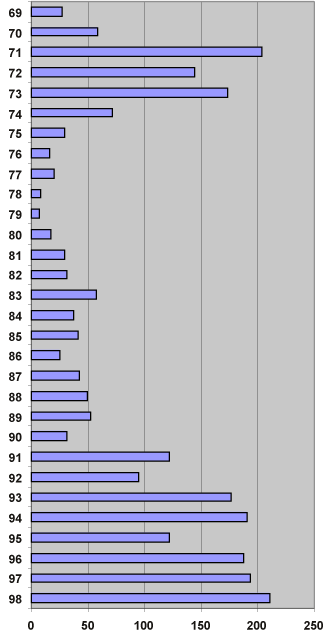
Should it be allowed to post documents which are not approved by IETF
as RFCs? Example: When people get their standards proposals rejected
by IETF, they sometimes publish them as RFCs, and then refer to these
RFCs in marketing of their products, as if they had been approved. Should
anyone be allowed to publish whatever they want as an RFC?
Someone proposed that we should have a separate series
of "harmful" or "not recommended" proposals. Someone
else said that it was enough to publish an additional RFC explaining
why another RFC is harmful.
|
|
LDAP Extension BOF
|
| |
Agenda
- Draft progress: MTI (authentication method, digest, TLS)
- Language tags, dynamic, simple proposal
- Access control
Should each application use its own access control
methods? Should there be a standard way to set up an encrypted session?
The Open group has developed a requirements document for authentication
APIs.
- C API
Draft has been around for a long time, and is widely
deployed. There is a tradeoff between compatibility and perfection,
there is pressure from both sides. Current draft is useful and has
many interworking implementations, so it is difficult to change
it even if the ideal API should be different.
Threading and TLS will be handled through the
extension mechanism. This mechanism is almost ready .Reformat client
control should be addressed now. SASL API can be handled later.
Rebind callback should be addressed now. LDAP session options has
a number of small problems, but generally works well.
Which C version should it be based on? ISO C (the
current accepted standard) is stable and well-defined, but some
implementations are not compatible with that standard.
- Signed directory operations
- Referrals & KRS
- Duplicate entries/sorting
If you display a list, such as an address book,
how should you sort if the sorting key is multi-valued? Proposal:
Sort it into all the places, i.e. split the entry.
- "Related attributes" = "collections of attributes"
= "compound attributes"
If you have multiple addresses, and multiple attributes,
how do you know which of the multiple attributes is paired with
which of the multiple addresses?
Solution 1: Nested attributes, each nest
level is called a compound attribute or an attribute group.
Solution 2: Families of entries in the directory
tree. This solution requires two new object classes, parent and
child.
Each of these solution has different pros
and cons.
Example: Filtering should fail, if it matches
only combination of values in different groups.
A straw vote seemed to indicate that the
families of entries solution was mostly liked by those present at
the meeting.
- X.500 2000
New features which are expected:
- There is in reality today no global namespace.
- How can X.500 be run over TCP/IP?
- Support for F.520
- Multi-master replication
- Java API
- Persistent/triggered search
- AOB
An issue, that was mentioned at many of the agenda items above, was
whether various issues should be solved by the IETF LDAP group, or by
the ITU/ISO X.500 group.
|
|
Revision of the basic e-mail standards
|
| |
The drums documents are now very close to final publication. They will
be sent for working group last call in December, aiming at submitting
them for IESG last call on January 8, 1999.
Some late issues:
Unclear text in the SMTP document on whether you are allowed to bounce
a message because it seems to be a spam.
Text about when Message-ID should be changed can
be misunderstood, and will be clarified, but without specifying exactly
when the Message-ID should be changed and not changed.
Text about "Re: " should
more clearly indicate that translations of "Re: "
to other languages is not recommended.
Changes at this late date will only be considered
if supported by at least four people (a compromise between three and
five which were suggested at the meeting).
Future work on e-mail standards
We discussed whether there is other future work on e-mail standards.
The issue of most interest seems to be mailcap, a way of using directory
systems to find out the capabilities of a receiver's e-mailer (like
fax, color resolution, language, charset, PGP-support, public key, voice
capability). Other issues mentioned:
- Revision of Delivery Status Notifications. (Why does so few clients
support it? Are positive notifications really needed?)
- Routing slips (=circulation lists, workflow applications)
- 821 recipient list extension (allow more than 100 recipients in
one line)
- Server authentication
- Loop control
- How to get DSN implemented and used
- Security for executable code sent in e-mail
- Filtering
- Administration of mailing lists including the possible use of LDAP
- Mailing lists (a rathole!)
No decision was taken except that mailcap which has a mailing list
(write to mailcap-request@cs.utk.edu to subscribe).
|
|
DAV (Distributed Authoring and Versioning),
DASL, Searching and Locating WG
|
| |
Web page: http://lists.w3.org/archives/Public/www-webdav-dasl/
Queries and results in DAV are expressed in XML. This simplifies the
use of character sets. All XML is in Unicode format, or is transformed
to Unicode format before doing operations on it.
- Current documents:
- draft-henderson-dasl-scenairos
- draft-davis-dasl-requirements
- draft-reddy-dasl-protocol
Requirements:
These are requirements of what
the language defined must support, not what each
implementation MUST support. So
a MUST requirement here can become an OPTIONAL function in the protocol.
SHOULD means that the group might not include it in the standard if
they cannot find a good way of specifying it. (An interesting use of
the words SHOULD and MUST in a standards-requirement document. Is it
priority categories?) This is not
the definition of SHOULD and MUST in RFC 2119. There was a very long
discussion on this. We should not mix use of SHOULD and MUST in this
meaning with the RFC 2119 use of the words, otherwise the document will
be completely incomprehensible. Some people wanted us to remove the
words MUST and SHOULD from the requirements document.
- It MUST be possible to specify at least one resource in the scope.
It SHOULD be possible to specify a set of distinct, unrelated resources
in the scope.
- It MUST be possible to specify a WebDAV collection as a scope.
- It SHOULD be possible to specify other types of resources in a scope.
- When the scope is a collection, it MUST be possible to specify the
depth.
Criteria:
- It MUST be possible to search properties in a query. It MUST be
possible to search both DAV-defined and application-defined properties.
- It MUST be possible to search content in a query.
- It MUST be possible to search both properties and content in a single
query.
- It MUST be possible to combine criteria using Boolean operators.
- It must be possible to include undefined properties in a query without
error.
- It MUST be possible to test whether a property is defined.
- It MUST be possible to compare property values.
- It SHOULD be possible to compare property values to other properties
of other resources.
- It SHOULD be possible to compare property values to results of expressions.
- It MUST be possible to match property values with pattern matching,
at a minimum, string-ending wildcards. More powerful patterns, such
as defined by the SQL "like" operator or Unix regular expressions,
are desirable. For example, "text/*" to search on the media
type.
- It MUST be possible to use equality operators.
- It MUST be possible to use relative operators.
- It MUST be possible to specify case sensitivity.
- It MUST/SHOULD be possible to specify language-specific definitions
for string comparison and sorting.
This caused a long discussion. Do all languages have a sort order?
Is there a need for sorting algorithm specification standards? Do
such standards exist? Should sorting algorithm be specified by saying
"France French sorting order" or "use sort algorithm
A" or "use the sort algorithm described by the string 'XYZ'
in the ABC sort algorithm specification language". All this applies
to both sorting and comparison.
- It MUST be possible to search content of any text media type. "Searching
content" means locating sequences of character in the contents
of a resource.
Search is done on the content, not the transfer-encoded text. Systems
which store text in encoded format must index them in uncoded format
or allow on-the-fly-un-encoding when searching.
- It SHOULD be possible to search for words that are within a specified
number of words of each other.
Many people wanted this changed to MUST.
- It SHOULD be possible to search for words that occur within the
same grammatical context, e.g. same phrase, sentence, or paragraph.
- It SHOULD be possible for a client to control whether content searches
does or does not use a stemming comparison.
- Phonetic similarity,
- keywords,
- sort specification,
- set of properties to be returned (not all properties),
- limits on resources consumed in creating or transmitting in the
result set.
- Limit the number of records in the result set.
- Return fewer result records than match the criteria.
- Request paged results.
- Multiple query language grammars.
- MUST be possible to extend the basic grammar defined by DASL.
- MUST be possible for the server to redirect a query.
- SHOULD be possible for the client to request hit highlighting.
Extensibility: Allowing future standards to extend, or allow implementors
to extend without IETF approval?
Query Grammar Discovery Example
Request
OPTIONS / HTTP/1.1
HOST: www.myserver.com
|
Response
HTTP/1.1 200 UK
PUBLIC: GET, PUT, HEAD, SEARCH, ...
DASL: <DAV:basic search>
DASL: <http://foo.bar.com/mysearch>
|
Basic Search Syntax
Query components:
- select
- from
- where
- orderly
Example: Retrieve the content length values for all resources located
under the "/container1/" URI namespaces whose length exceeds
10000. Example of a short part of the translation of this to the query
language:
<where>
<gt>
<prop><Getcontentlength/></prop>
<literal>10000</literal>
"where" Expressions
Uses three-valued logic (includes null)
Operators:
- eq, gt, gte, lt, lte
- and, or, not
- literal (for constants)
- isdefined (tests whether property is defined)
- like (simple wildcard, Example: "image%")
- contains (full text search)
Contains is intentionally underspecified.
Does not define exactly what is meant by full text search. For example,
truncation, case-insenstive search, name interpretation, stemming, thesaurus
expansion, near constraints, phonetic comparison is not yet defined.
Range Requests
Not in protocol spec - Proposal on list
SEARCH /container/ HTTP/1.1
Range: rows=20-30
Or
SEARCH /container/ HTTP/1.1
Range: rows=20-end
Structured Property Query
"There are umpteen numbers of proposals for XML query languages,
XQL is one of them."
Complicated issue, DAV already defines several structured properties:
DAV:resourcetype
DAV:lockdiscovery
XML query is a current work area of W3C. They are doing important work
which we should use if possible.
|
|
Message Tracking Protocol
|
|
| |
A more complete description of these issues can be found in my notes
from the previous IETF meeting in Chicago.
This working group meeting started 19 minutes late,
because no chairman or other person was present representing the people
behind the proposal. The meeting was started by one of the area directors,
Keith Moore, who said that since we are here, we could have some discussion
of these topics anyway.
The DSN standard allows the sender of a message can
request a notification if the message was delivered or not delivered
to its final recipient. The Message Tracking Protocol is a proposal
for doing more detailed tracking of what happens when messages are forwarded.
This would be an aid to administrators of mail systems in order to investigate
problems with messages.
One feature was putting a cookie in a message, which
you can later on use to authenticate that you was the sender of this
message. This might solve some of the security problems with the proposal
in the Chicago meeting.
The intention was not only to ask for tracking of
a new message, but also to be able to track afterwards what has happened
to an already sent message.
Three alternative methods:
- Trusted third party stores trace reports from all MTAs passed. Has
scalability problems.
- DSN-style reporting, i.e. messages sent back to the sender at each
hop.
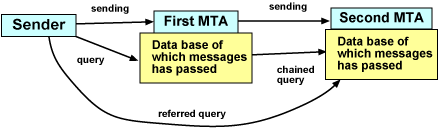
MTA queries, i.e. you can ask an MTA what has happened with a message.
This requires a data base in each MTA of which messages have passed
it. Such a data base might also be used for loop control.
- chaining, sender queries the first MTA, which then queries the
next MTA.
- referral, sender queries the first MTA, which tells the sender
which is the next MTA, so that the sender can query that server.
To reduce cost, one might let senders mark messages as traceable, and
only save trace information for messages marked in that way.
There are cryptographic methods for ensuring that
only the original sender can trace his message, including facilities
for a user to delegate this authority to other people. These methods
are discussed in the usefor group, which is planning to use them to
check that only authorized people can cancel articles.
|
|
Human-Friendly Names/Identifiers BOF
|
| |
Note: This presentation is ideas from various drafts, not
final solutions
Problem space description
Larry Masinter:
What problems can we solve? The URL syntax is unfriendly
for non-experts. Internationalization: Exact match doesn't work for
non-English, Élan=élan=Elan.
Services with collections of names:
Titles of books, names of medical conditions, trade names.
Software for name entry: Browsers,
address books. Simple, unsatisfactory first attempts: Search engine
interpret "ibm" as "http://www.ibm.com". More advanced
features in new browsers.
Search engines: Searching content,
name matching.
The above services are sometimes combined.
Defining uniqueness: Impossible,
user type in so short names that they cannot be unique.
Creating authorities: Avoid political
winds.
Registration mechanism: May wary
between name spaces.
One operational model:
- user types something in native language
- some kind of matching with choices
cannot be standardized yet
today, open to innovation
- choices are unique but still friendly
- choice is mapped to a URN
- the URN is mapped to a URL
- the resource is accessed
Summary:
- We can solve some real problems
- Systems exist, interface standardization needed
- Stick to what's common, leave open the parts that are not
- Avoid politics
Presentation of
identifiers
Presentation of existing drafts, draft-mealling-human-friendly-identifier-req-00.txt.
Requirements document: Users (what
are they willing to accept, people like you, me or your grandmother),
Marketing (advertising interest), Trademark (like users, but have more
lawyers).
Justification: HTTP URLs and domain
names are not viable identifiers for unsophisticated users, and the
unsophisticated users far outnumber the sophisticated users. Marketing,
trademark and user communities attempt to force URLs and domain name
systems into what they want, but what may not work so well on the net.
Ratholes:
Do not develop a generic directory service, do not become a trademark
enforcement activity.
General requirements: The names
should be as short as possible, they should be fully internationalized,
the names will be non-unique, a single name can match a multiple of
separate resources.
Matching time: 1-2 seconds maximum.
Matching semantics: Must allow
substrings. User should be able to specify geographic limitations.
Openness: Open way of inserting
your own names, quality of name registration, user should be able to
understand how much vetting is done.
Architecture
Components: Root is a flat namespace,
so someplace for the names to reside is needed.
Registrars: Can write qualified
entries into the root. You can input unvetted names, but qualified names
are listed first in result listings.
Content servers: Data outside the
root.
Local servers:
Just like in DNS, a user can use a local server for locally scoped
names. Client: Can maintain context information.
The "go" URI scheme;
examples:
- go:Nike
- go:IETF
- go:Martin%20J.%20D%C3%BCrts (not what user sees, but what is sent
on the wire)
The RealName system:
An example of a human-friendly-name system
(Centraal corporation) A real name
is a company name (example: "Walt Disney"), or a brand name
(example: "M&M"), or an advertising slogan (example: "just
do it"). These are names, which marketing has spent a lot of effort
on getting people to know.
Can we use URLs? Can we use URNs? Not quite.
Some companies are highly persistent, but not all
companies are persistent. Persistence might be promised for a certain
time, for example one year.
Services are emerging, for example "smart browsing"
from Netscape.
(Dunn & Bradstreet) Plug-in
exists for Internet Explorer. Problems is that people want to use abbreviations,
and not the full name, like for example "IBM" instead of "International
Business Machines".
Advice: Do not design complex protocols
which people cannot use. Avoid showing the URLs to the users.
Discussion
Why did you not use my protocol? Answer: We tried LDAP, it was too
slow. How can different services with separate real name data bases
cooperate? Is there anything which needs standardization here? Or should
we leave this to the market?
One speaker: People claim that the DNS cannot be
used because it does not allow international characters. That is wrong.
The limitation on character set only applies to domain names. If you
use the DNS for other things than domain names, you can use any 8-bit
string. You can even implement fuzzy matching, even though typical DNS
servers today do not support fuzzy matching.
Who will pay for this?
A new IETF working group?
This was on the last hours of the IETF meeting, so many people did not
come, there was only about 30 people present, but about 10 of these wanted
to do work on standards in this area, so a new IETF working group will
probably be formed. |
|